Agile AI Engineering
Accelerate your knowledge discovery with an integrated development and experiment platform.

Low-code tools are going mainstream
Purus suspendisse a ornare non erat pellentesque arcu mi arcu eget tortor eu praesent curabitur porttitor ultrices sit sit amet purus urna enim eget. Habitant massa lectus tristique dictum lacus in bibendum. Velit ut viverra feugiat dui eu nisl sit massa viverra sed vitae nec sed. Nunc ornare consequat massa sagittis pellentesque tincidunt vel lacus integer risu.
- Vitae et erat tincidunt sed orci eget egestas facilisis amet ornare
- Sollicitudin integer velit aliquet viverra urna orci semper velit dolor sit amet
- Vitae quis ut luctus lobortis urna adipiscing bibendum
- Vitae quis ut luctus lobortis urna adipiscing bibendum
Multilingual NLP will grow
Mauris posuere arcu lectus congue. Sed eget semper mollis felis ante. Congue risus vulputate nunc porttitor dignissim cursus viverra quis. Condimentum nisl ut sed diam lacus sed. Cursus hac massa amet cursus diam. Consequat sodales non nulla ac id bibendum eu justo condimentum. Arcu elementum non suscipit amet vitae. Consectetur penatibus diam enim eget arcu et ut a congue arcu.

Combining supervised and unsupervised machine learning methods
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
- Dolor duis lorem enim eu turpis potenti nulla laoreet volutpat semper sed.
- Lorem a eget blandit ac neque amet amet non dapibus pulvinar.
- Pellentesque non integer ac id imperdiet blandit sit bibendum.
- Sit leo lorem elementum vitae faucibus quam feugiat hendrerit lectus.
Automating customer service: Tagging tickets and new era of chatbots
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
“Nisi consectetur velit bibendum a convallis arcu morbi lectus aecenas ultrices massa vel ut ultricies lectus elit arcu non id mattis libero amet mattis congue ipsum nibh odio in lacinia non”
Detecting fake news and cyber-bullying
Nunc ut facilisi volutpat neque est diam id sem erat aliquam elementum dolor tortor commodo et massa dictumst egestas tempor duis eget odio eu egestas nec amet suscipit posuere fames ded tortor ac ut fermentum odio ut amet urna posuere ligula volutpat cursus enim libero libero pretium faucibus nunc arcu mauris sed scelerisque cursus felis arcu sed aenean pharetra vitae suspendisse ac.
AI engineers are poised to make the most significant impact on their businesses as foundation models become core to the user experience and are optimized not for performance in academic benchmarks but for lifting user engagement metrics and business KPIs.
Data-driven tech companies like Yelp are finding that simply choosing a frontier model optimized for a user-base of developers doesn't translate to a better user experience for Yelpers.
The design space of practical AI engineering tasks can include data curation, model selection, fine-tuning, prompt engineering, model evaluation, and inference optimizations. Most foundation model providers offer limited visibility into key determinative performance factors, such as the data used to train the model. To understand your AI, you must first recognize that AI is an empirical discipline and that finding the best treatments requires testing.
A best practice for improving over the current state-of-the-art foundation model starts by finding the best model for your application from the world of open-weight contenders. Most new results in AI follow this simple pattern of comparing the top-N most relevant AI models for a given capability and showing an improved state-of-the-art by applying some novel treatment effects. Often, enhancements involve additional fine-tuning with high-quality data samples, including instances of ideal reasoning traces that are more specific to your use case.
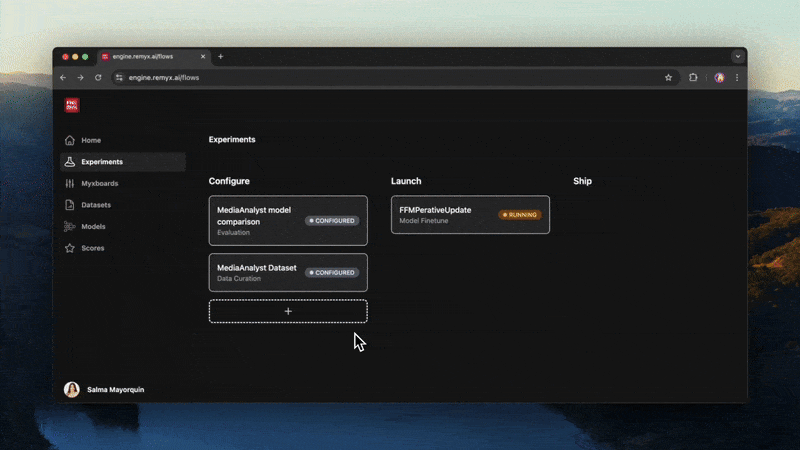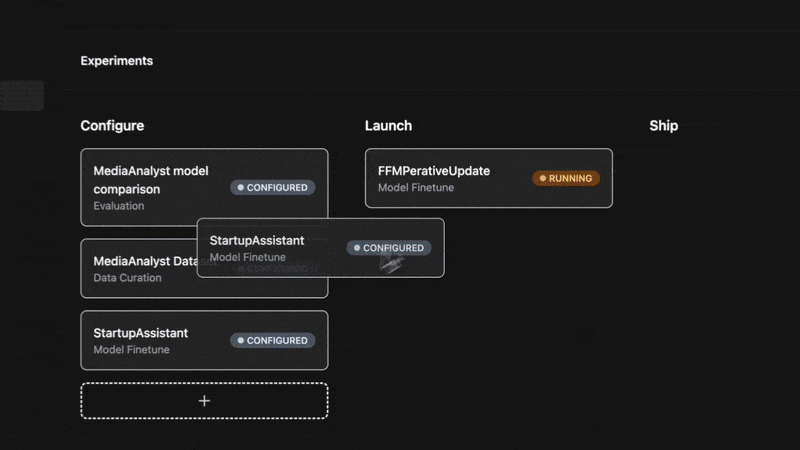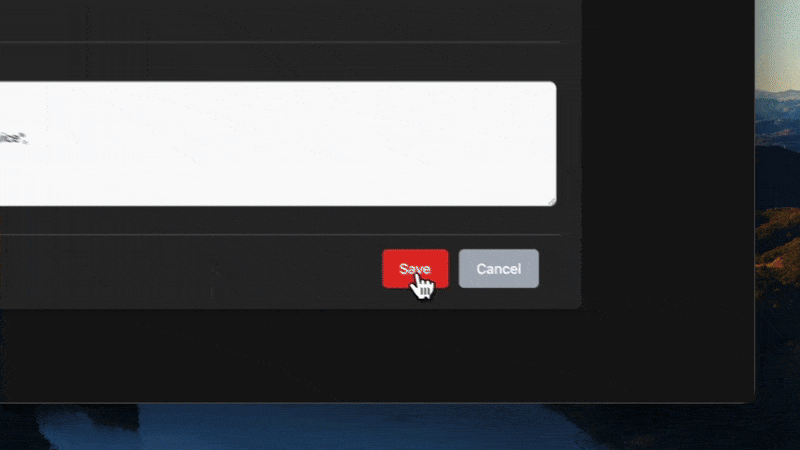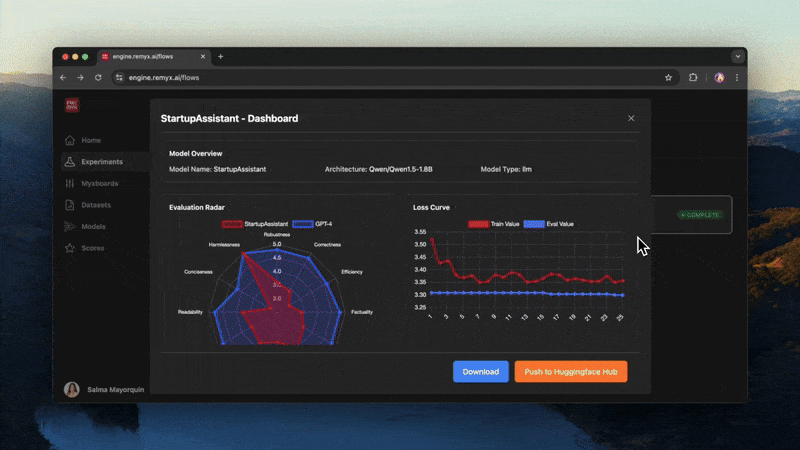
The challenge lies in robust and trustworthy evaluations to find the best data and model artifacts. Neither the shape of the loss curve nor the scores on an academic benchmark are reliable predictors of how your AI will drive user engagement or meaningfully impact your business KPIs. Generic Judges and juries are no substitute for A/B testing, the gold-standard evaluation method for software engineering. Instead, teams will compare candidate models meeting practical engineering requirements like latency. Evaluation will be holistic, considering metrics like benchmarks relevant to the key capabilities and application-specific synthetic datasets evaluated using judges. These methods will help teams develop confidence in the lead-up to choosing treatments for their users to assess through an online controlled experiment.
Optimizing these data and model artifacts has become less reliant on code than configuration. The ideal space to collaborate and form consensus for the next experiment is not the notebook but a more agile interface using a Kanban board. Collaborating this way, teams can configure, launch, and ship AI app features by updating metadata in a card. By applying a panel of progressively more specific offline evaluation techniques, they'll have the tools and evidence to more efficiently explore what works after pruning potential candidate treatments. Ultimately, you want to learn what's important for your users so you can double down on maintaining what works and iterate faster on the ideas that drive business value.
Agents have a role in helping to maintain the flow, not merely as chatbots but as proactive partners in scientific discovery. An agent with the context of institutional knowledge discovered through treatment failures and successes will be well-poised to curate and socialize the learnings. Your team will collaborate with agents that can recommend your next great experiment, matching your interests to what is relevant from sources like arXiv and HF papers. Agents conditioned on industry best practices, like Ronny Kohavi's custom GPT will help your team with tools to get the most trustworthy measurements for decision making, see this post.
At Remyx AI, we're reimagining the ideal IDE for developing AI applications. It's about integrated development and experimentation for closed-loop AI engineering and AI-organizational alignment. We envision a framework including APIs to integrate with your Trello or Notion, as well as your Hugging Face or GitHub accounts, to leverage the full context of your AI program and extend your team's capabilities for knowledge discovery.
How do you measure success? I hope it's not simply lines of code! Most experiments launched cannot be associated with a statistically significant lift to metrics related to user engagement or business value. If you're not testing your AI, how do you know you aren't simply random-walking your customers into the arms of the competition?
As you consider your AI initiative, how do you measure success? What's your hypothesis?
#BeAnExperimenter
Don't just ship models. Learn how to build great AI. Experience ExperimentOps.

.png)
